


This is a guest post by Jeff Escalante. Jeff is a New York City based developer, working for Carrot Creative. He is also the creator of Spike, a modern static build tool, powered by webpack.
One of the great advantages of headless CMS' is that they are able to be consumed by a wide variety of different applications and build tools, rather than being tied specifically to a web frontend. And today we'll be talking about using GraphCMS to create a static site - an architecture that suits many use cases much better than using a dynamic site or single page app. We'll build the static site that consumes our GraphCMS data using Spike, a flexible static site generator built on top of webpack, and we will deploy to Netlify, the undisputed king of static hosting services.
The following figure shows the static site generation process in a nutshell:
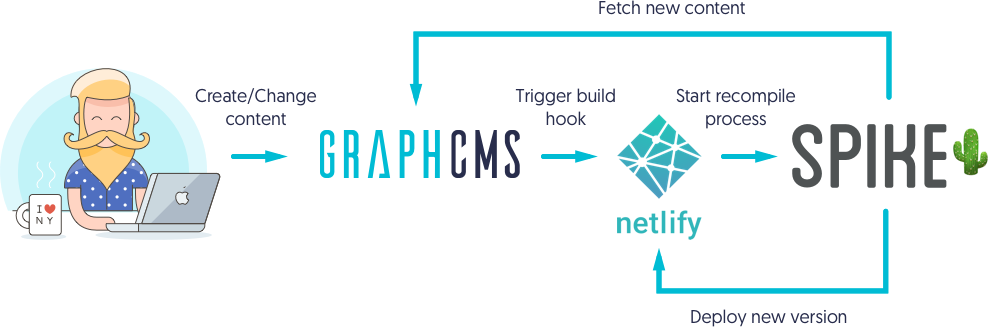
As an example project, we will clone Vinylbase, the canonical GraphCMS example site.
Intro to SpikeAnchor
Before we dive into the code, let's talk about spike for a minute, since it's the primary tool we're using to build the site. Spike is an extension of webpack that leverages webpack's core code in order to also compile html and css and operate as a normal static site generator. It is compatible with all webpack loaders and plugins, and its primary focus is flexibility and robust abilities to build sites with many sources of external data.
Spike uses babel, postcss, and reshape as its core loaders and languages. All three of these projects do the same thing - parse html/css/js, expose its AST for plugins to operate on, then generate to html/css/or js. This means that it's very easy to transform html, css and/or javascript exactly in the way you want.
While this ability is incredibly powerful, it can also be problematic since with unlimited configurability comes an unlimited number of configurations. Often times, having standards and conventions can help developers to not have to learn a totally different language from scratch, each site they work on. For this reason, Spike ships with a set of standards (or presets) that bundle up sets of commonly used plugins and allow for simple, convention-based builds. Check out how slim and simple spike's default configuration is:
const htmlStandards = require('reshape-standard')
const cssStandards = require('spike-css-standards')
const jsStandards = require('spike-js-standards')
module.exports = {
matchers: { html: '(**/).sgr', css: '(**/).sss' },
ignore: ['/layout.sgr', '/_', '**/.', 'readme.md', 'yarn.lock'],
reshape: htmlStandards(),
postcss: cssStandards(),
babel: jsStandards()
}Just a few lines - not bad right? But under the hood, these presets use over 100 plugins across babel, postcss, and reshape. That is the power of convention ?.
Consuming External DataAnchor
Ok, let's talk about how we can get spike to consume external data -- specifically GraphQL data from GraphCMS. We'll be using a general purpose data consumption plugin called Spike Records in this example. The way it works is essentially that we pass it an object that we can also pipe into our html as local variables, and some GraphQL queries, and spike-records will make the query and add it to our "locals" object so that it's available in our views. Let's check out the basic configuration for this:
const Records = require('spike-records')
const locals = {}
module.exports = {
reshape: htmlStandards({ locals: (ctx) => locals }),
plugins: [
new Records({
addDataTo: locals,
reviews: {
graphql: {
url: 'https://api.graphcms.com/simple/v1/vinylbase',
query: `{ allReviews { title } }`
}
}
}
)]
}So up top, we require spike-records and create an empty locals object. We pass the locals object into the reshape configuration to make it available in our html templates, then also pass it to the addDataTo option in spike records. This ensures that the two are connected - spike records fetches remote data and adds it into our views. After this, we add a standard GraphQL query and a URL, and that's all it takes! Our response object will now be available under reviews in our html templates.
In the real project we're doing a little more than this. First, we are making three different requests - one for each major model type (reviews, records, artists). Second, since GraphQL responses come back wrapped in data.allXXX by default, and we don't need this extra wrapper, we use a transform function to shed it and go straight for the data we need. Finally, we use a template option to write out each record returned to its own individual template. This way, we have single pages for each review, artist, and record. For further details on these configuration options, check out the documentation for spike-records.
Now let's talk about using the data in our templates. By default we use sugarml for whitespace-significant html (can easily be turned off), and reshape-expressions to evaluate local variables and expressions, which use a (configurable) double curly bracket syntax. So to see some of our reviews, we could add code like this:
p {{ JSON.stringify(reviews) }}And to loop through our reviews, like this:
each(loop='review in reviews')
h3 review.titleFrom here we can move forward with building out our front-end structure!
Deploying Our SiteAnchor
Let's fast forward to the point where we've built out all the pages and we're ready to deploy. We're going with Netlify for this site, since it's clearly the best option for static hosting, and works particularly well with Spike and GraphCMS.
In order to deploy any static-generated site to netlify, you need to first make sure the static generator is a dependency, so that netlify gets a copy of it which it can use to compile. This means running yarn add spike, and we should be ready to roll. Push your site to github, gitlab, or bitbucket, link it up through netlify, make your build command spike compile, and public directory public, and you should be ready to go. Easy enough!
Keeping Our Site Up To DateAnchor
Ok, so we have built and deployed a static site based on GraphCMS data - pretty awesome. But what happens when the data changes? Our site is static, so we have an issue here, right? Not once you take webhooks into account! By connecting GraphCMS' webhooks to Netlify's build hooks, we can make it such that whenever there is a change to the data on GraphCMS, it notifies Netlify, our host, which will recompile the site based on the latest data. So basically, rather than pulling the data down and generating a template each time the users makes a request to the site, it is generated once and only recompiled when the data changes. This is the magic of static ✨.
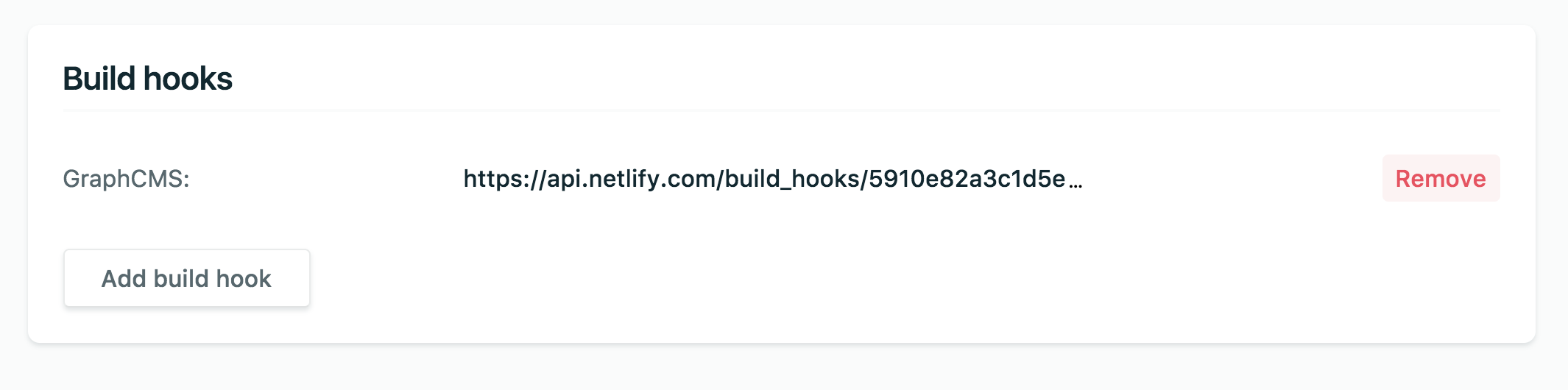
Let's start with Netlify. Jumping into our app interface, we can create a build hook, which we will later give to GraphCMS to hit when something has changed.
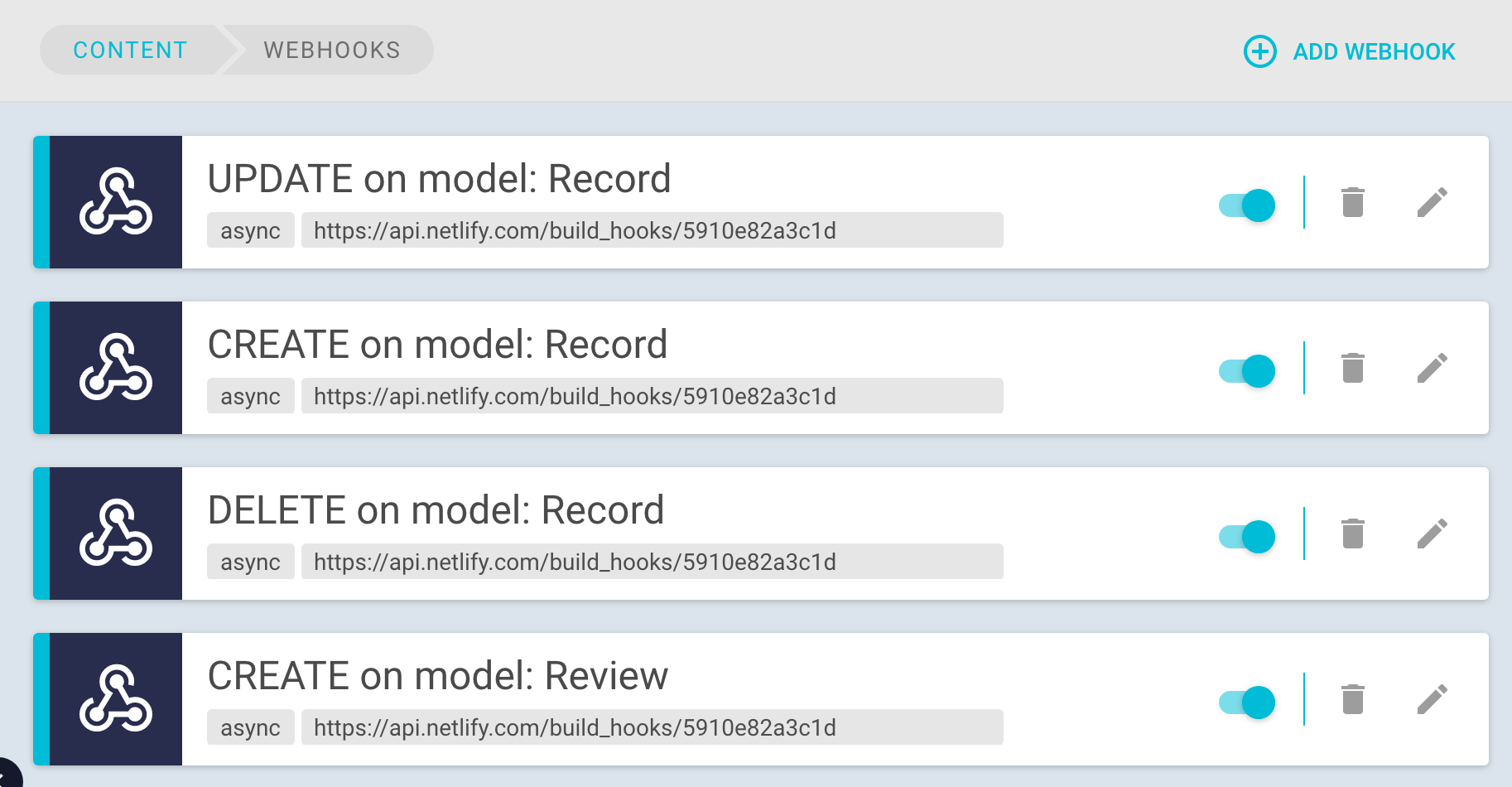
Now, over in our GraphCMS interface, we set up some webhooks. Since GraphCMS doesn't currently have an option to fire a single webhook for any change, we need to add individual webhooks for each type of change to each model. That being said, a feature request has been made for a single webhook that catches changes on all models, and the GraphCMS team said that they were happy to deliver this feature within the next few weeks ?
...and that should do the trick! To test this out, we can make a change in GraphCMS, then flip over to the netlify dashboard and see that a new build has kicked off. A few seconds later, the site content has updated.
Static for the WinAnchor
That's all it takes to produce a cms-powered static site - not bad right? Not only do you not have to run a server at all, but you get blazing fast performance, the cheapest possible hosting, zero javascript, and the ultimate standard for developer accessibility - your architecture is just flat html, css, and javascript which no web developer will ever need to learn and will never go out of style.
GraphCMS and Netlify are a perfect combination for this type of build. The webhook integration allows for simple updates, using GraphQL allows you to quickly pull exactly the data you need for your templates, and Spike lets you integrate the two seamlessly. In fact, I'd argue that going static is actually a better architecture than the original vinylbase example which used react, since heavy interactivity isn't necessary, and the entire site was easily built without a single line of client-side javascript.

